
Vcluster ist ein voll funktionsfähiger Kubernetes-Cluster, installiert in einem Kubernetes-Cluster. Während der Nutzer in einem Namespace oder über ein Rancher Projekt in mehrere Namespaces Zugriff hat und ihm cluster-weite Resourcen verwehrt bleiben und so etwa keine CRDs oder Mutation-Webhooks installiert werden können, soll er im vcluster vollen Zugriff erhalten. Wie weit das wirklich funktioniert und welche Einschränkungen es gibt, schauen wir uns hier mal an.
Was sofort funktioniert:
vcluster create my-vclusterWir wollen allerdings eine etwas sichere Methode wählen, die auch mandatenfähig ist. Zur Verwaltung mandatenfähiger Cluster mit zentraler Userverwaltung hat sich Rancher etabliert. Wir brauchen also:
In diesem Namespace können wir vcluster installieren. Neben der Installation mit dem vcluster cli gibt es eine Installationsvariante mit Helm. Hier ist unser values.yaml
vcluster:
image: rancher/k3s:v1.23.5-k3s1
securityContext:
runAsUser: 1000
runAsNonRoot: true
allowPrivilegeEscalation: false
capabilities:
drop:
- all
readOnlyRootFilesystem: true
fsGroup: 1000
Den vollen Konfigurationsumfang des Charts kann man hier sehen. Zu beachten ist noch, dass vcluster verschiedene Cluster-Typen kennt: eks, k8s, k0s, k3s. Wir benutzen k3s.
Jetzt die Installation:
helm -n vcl1 upgrade -i cl1 vcluster --values values.yaml --repo https://charts.loft.sh
Überprüfung:
$ vcluster list
NAME NAMESPACE STATUS CONNECTED CREATED AGE CONTEXT
cl1 vcl1 Running 2022-12-01 15:21:35 +0100 CET 28s frank-test-k8s-12
Das wars schon.
Wir können den vcluster in Rancher importieren, indem wir die Importfunktion im Rancher benutzen. Es wird eine Deploy-URL generiert, die wir im vcluster ausführen:
vcluster -n vcl1 connect cl2 -- kubectl apply -f https://k3s.otc.mcsps.de/v3/import/hjjnrlmj9xfsmw7wctsdpr7b6ftc5gkfr9fqv7rlvshzzj86f46q_c-m-84h8jjd7.yaml
Hier taucht schon das erste Problem auf. In einem Downstream-Cluster mit verschiedenen Projekten und Namespaces kann ich verschiedene Sicherheitsrichtlinien festlegen. Systemnahe Dienste wie die Rancher-Agenten laufen im System-Projekt und dem cattle-system Namespace. Dort können sie sich in aller Ruhe ausbreiten, ohne die Restriktionen eines Projekts mit einer Nutzer-Webapp.
Der vcluster läuft in einem Namespace des Downstream-Clusters und dort mit der festgelegten Restriktionen wie PodSecurityPolicy oder Resource Quota. Man muss also entscheiden, ob dieser Cluster dann vollständig in diesem Modus laufen kann oder etwa eine unrestricted PodSecurityPolicy benötigt. Ab Kubernetes 1.23 kann man über den PodSecurityAdmissionController dieses Feature als Namespace Annotation setzen. Man könnte also auf dem Host-System weniger restriktiv sein, dann aber im vcluster bestimmte Namespaces per Annotation einschränken.
Für den Rancher Agenten können wir uns behelfen, indem wir im Deployment die Affinity löschen und den securityContext anpassen.
spec:
template:
spec:
container:
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
securityContext:
fsGroup: 1000
Dann haben wir den vcluster im Rancher:
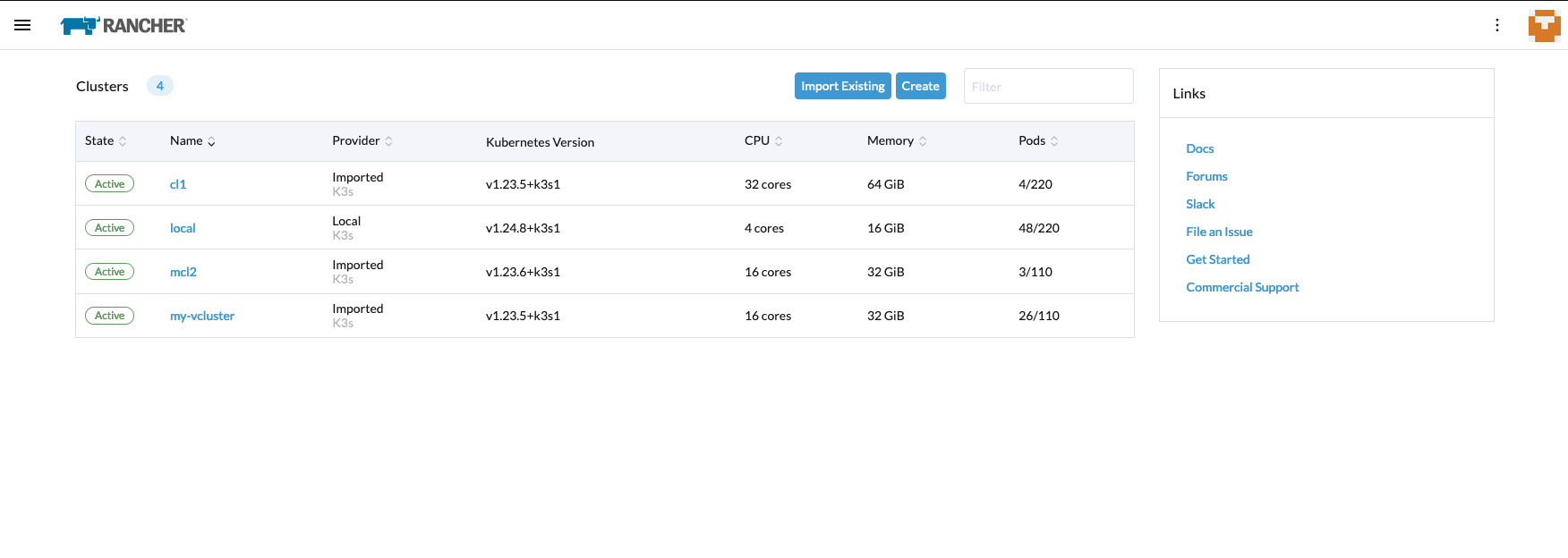
Upps, haben wir jetzt noch einen vcluster im vcluster erstellt? Das ist möglich. Ich lade die kubeconfig für den ersten
vcluster herunter und in diesem Context rufe ich das helm upgrade -i nochmal auf, oder nutze vcluster create
Aber Obacht:
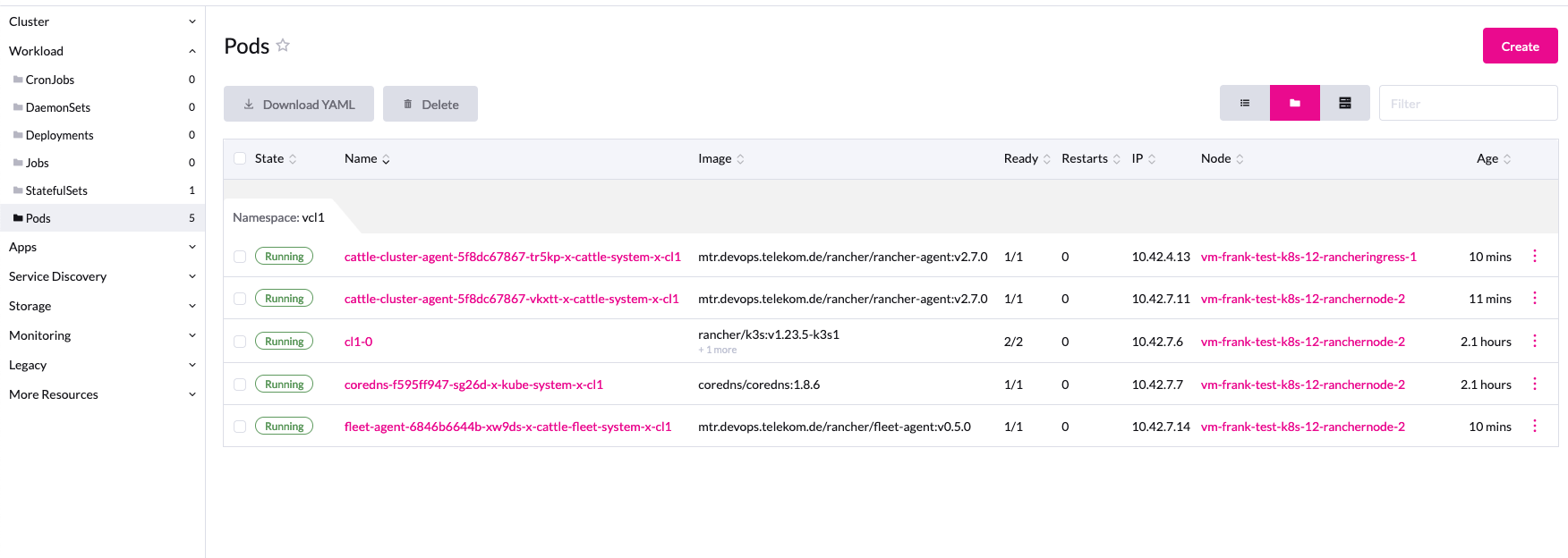
Die Resourcen werden im Upstream-Cluster mit vcluster Namen und Namespace angezeigt. Da diese Felder eine begrenzte Länge von 63 Zeichen haben, kann es schnell zu Fehlermeldungen im Kubernetes kommen. Deswegen sollte man immer kurze Namen wählen.
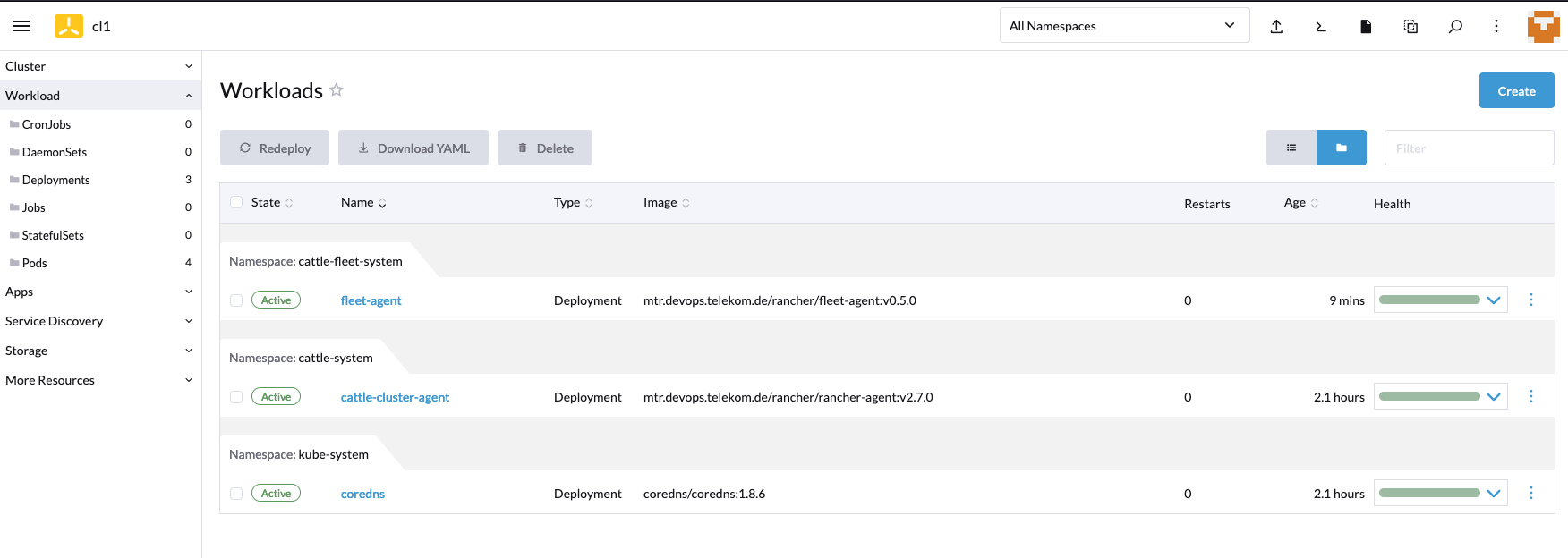
Die Workload im vcluster ist noch sehr übersichtlich, es läuft nur der Rancher- und der Fleet-Agent.
Spätestens bei den Netzwerkdiensten merkt der Nutzer, dass er nicht in einem echten Cluster ist.
Natürlich können Netzwerkdienste in der Virtualisierung nicht installiert werden. Aber mit der Option
--expose kann man einen Loadbalancer Dienst vom Downstream-Cluster beziehen und wenn dort etwa ein
Cloud Controller Manager dranhängt, bekommt man auch die public-IP in den vcluster.
Hier mal die Installation mit vlcuster cli:
$ vcluster -n vcl1 create cl2 -f values.yaml --expose
Kontrolle:
$ kubectl -n vcl1 get services cl2
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cl2 LoadBalancer 10.43.112.229 80.158.88.16 443:30583/TCP 2m19s
Eine andere Möglichkeit sind mapServices. Diese Option kann man im values.yaml bei der Installation mit angeben. Es werden dann entweder Services vom Host zum vcluster gemapped oder umgekehrt:
Beispiel cert-manager:
mapServices:
fromHost:
- from: cert-manager/cert-manager
to: kube-system/cert-manager
Über den Helm Value
isolation:
enabled: true
kann man eine NetworkPolicy für den vcluster definieren, als auch ResurceQuota und LimitRanges. Neben den Standardwerten des Charts kann man diese natürlich auch überschreiben.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: release-name-workloads
namespace: vcl1
spec:
podSelector:
matchLabels:
vcluster.loft.sh/managed-by: release-name
egress:
# Allows outgoing connections to the vcluster control plane
- ports:
- port: 443
- port: 8443
to:
- podSelector:
matchLabels:
release: release-name
# Allows outgoing connections to DNS server
- ports:
- port: 53
protocol: UDP
- port: 53
protocol: TCP
# Allows outgoing connections to the internet or
# other vcluster workloads
- to:
- podSelector:
matchLabels:
vcluster.loft.sh/managed-by: release-name
- ipBlock:
cidr: 0.0.0.0/0
except:
- 100.64.0.0/10
- 127.0.0.0/8
- 10.0.0.0/8
- 172.16.0.0/12
- 192.168.0.0/16
policyTypes:
- Egress
---
# Source: vcluster/templates/networkpolicy.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: release-name-control-plane
namespace: vcl1
spec:
podSelector:
matchLabels:
release: release-name
egress:
# Allows outgoing connections to all pods with
# port 443, 8443 or 6443. This is needed for host Kubernetes
# access
- ports:
- port: 443
- port: 8443
- port: 6443
# Allows outgoing connections to all vcluster workloads
# or kube system dns server
- to:
- podSelector: {}
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: 'kube-system'
podSelector:
matchLabels:
k8s-app: kube-dns
policyTypes:
- Egress
---
# Source: vcluster/templates/resourcequota.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: release-name-quota
namespace: vcl1
spec:
hard:
count/configmaps: "100"
count/endpoints: "40"
count/persistentvolumeclaims: "20"
count/pods: "20"
count/secrets: "100"
count/services: "20"
limits.cpu: "20"
limits.ephemeral-storage: "160Gi"
limits.memory: "40Gi"
requests.cpu: "10"
requests.ephemeral-storage: "60Gi"
requests.memory: "20Gi"
requests.storage: "100Gi"
services.loadbalancers: "1"
services.nodeports: "0"
---
# Source: vcluster/templates/limitrange.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: release-name-limit-range
namespace: vcl1
spec:
limits:
- default:
cpu: "1"
ephemeral-storage: "8Gi"
memory: "512Mi"
defaultRequest:
cpu: "100m"
ephemeral-storage: "3Gi"
memory: "128Mi"
type: Container
Wenn man K3s aus welchen Gründen auch immer nicht verwenden will, kann man vcluster auch mit plain K8S installieren.
Dazu werden alle Bestandteile wie Api, Controller, Scheduler und etcd separat installiert. Leider klappt das nur mit unrestricted
PodSecurityPolicy, oder man weicht die restricted auf mit CAP_NET_BIND_SERVICE.
Hier eine values.yaml
securityContext:
runAsUser: 1000
runAsNonRoot: true
allowPrivilegeEscalation: false
capabilities:
drop:
- all
readOnlyRootFilesystem: true
fsGroup: 1000
etcd:
securityContext:
runAsUser: 1000
runAsNonRoot: true
allowPrivilegeEscalation: false
capabilities:
drop:
- all
readOnlyRootFilesystem: true
fsGroup: 1000
controller:
securityContext:
runAsUser: 1000
runAsNonRoot: true
allowPrivilegeEscalation: false
capabilities:
drop:
- all
readOnlyRootFilesystem: true
fsGroup: 1000
scheduler:
securityContext:
runAsUser: 1000
runAsNonRoot: true
allowPrivilegeEscalation: false
capabilities:
drop:
- all
readOnlyRootFilesystem: true
fsGroup: 1000
api:
securityContext:
runAsUser: 1000
runAsNonRoot: true
allowPrivilegeEscalation: false
capabilities:
add:
- CAP_NET_BIND_SERVICE
readOnlyRootFilesystem: true
fsGroup: 1000
job:
securityContext:
runAsUser: 1000
runAsNonRoot: true
allowPrivilegeEscalation: false
capabilities:
drop:
- all
readOnlyRootFilesystem: true
fsGroup: 1000
scheduler:
securityContext:
runAsUser: 1000
runAsNonRoot: true
allowPrivilegeEscalation: false
capabilities:
drop:
- all
readOnlyRootFilesystem: true
fsGroup: 1000
syncer:
securityContext:
runAsUser: 1000
runAsNonRoot: true
allowPrivilegeEscalation: false
capabilities:
drop:
- all
readOnlyRootFilesystem: true
fsGroup: 1000
Und die Installation:
$ vcluster -n vcl1 create cl4 -f values.yaml --distro k8s
Kontrolle:
$ vcluster list
NAME NAMESPACE STATUS CONNECTED CREATED AGE CONTEXT
cl4 vcl1 Running 2022-12-01 23:25:21 +0100 CET 3m24s frank-test-k8s-12
Eventuell gibt es auch noch Beschwerden in der PSP wegen seccomp, weswegen man diese mit einer Annotation erweitern muss:
annotations:
seccomp.security.alpha.kubernetes.io/allowedProfileNames: '*'
Loft ist die Firma hinter vcluster. Und auch gleichzeitig eine Plattform, in der ich meine vcluster verwalten kann. Dazu muss man den loft-agent installieren und den loft cli. Mehr Informationen auf der Webseite loft.sh.
Mit loft start start man den Registrierungsprozess beim Loft Dienst. Der Agent leitet alle Anfragen weiter und zeigt
uns diese Verwaltungswebseite:
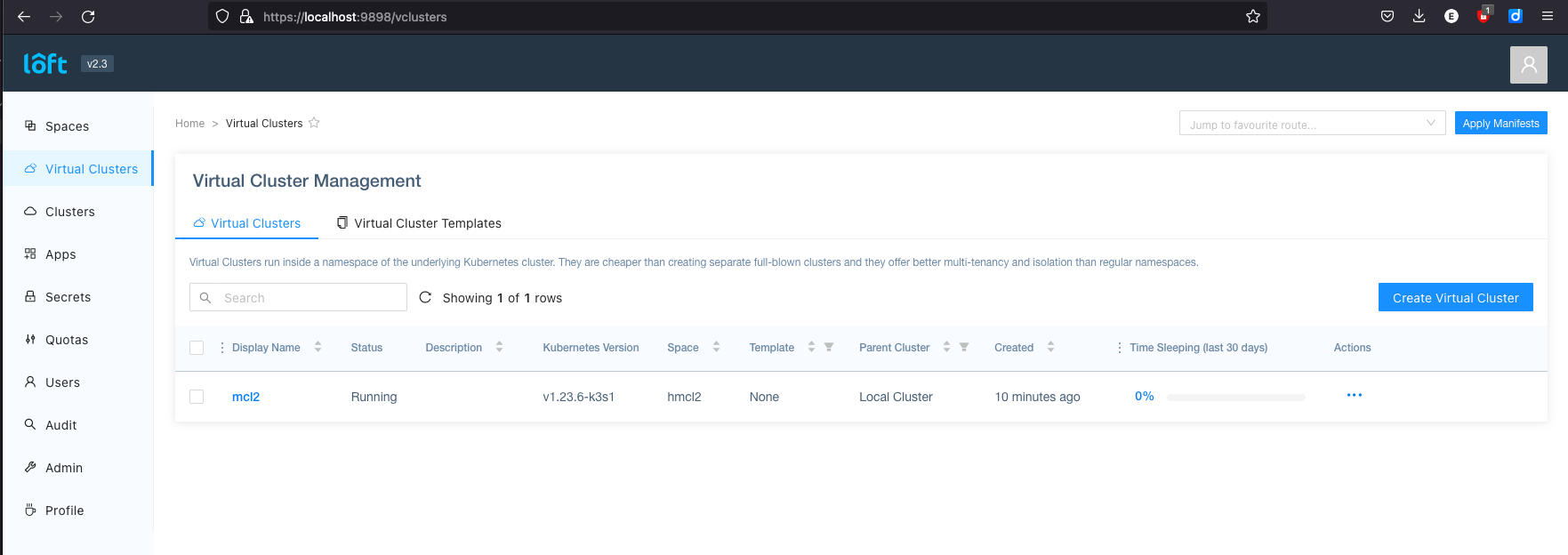
Vcluster ist eine weitere Virtualisierungsform in der Cloud-Landschaft, die Einschränkungen von Kubernetes bezüglich cluster-weite Resourcen in projektspezifische Namespaces überwindet. Die Zielgruppe sind also Nutzer, die vollen Cluster-Zugriff benötigen, um Admission-Controller, Operator und andere Anwendungen mit API-Erweiterungen (CRDs) installieren und auch betreiben möchten. Der normale Webentwickler wird mit einem Kubernetes-Namespace, in dem er seine Webanwendung deployen kann, zufrieden sein und alle anderen Dienste von einem Managed Service anfragen.