
Den Kubernetes Operator haben wir in diesem Artikel schon kennengelernt. Die Kubernetes-API wird mit eigenen Resource-Definitionen erweitert und kann quasi als Stanze beliebig oft verwendet werden. Der Prometheus Operator ist so eine Stanze, die Rancher, wenn man die App über den Marketplace installiert, in seinem Tool eingebettet hat und dennoch die Eigenständigkeit erkennen lässt. Praktisch zu erleben ist die Proxy-Funktionalität im Browser, wenn über die Rancher-Authentifizierung die internen Dienste Prometheus und Grafana angesprochen werden.
Als erstes muss die Anwendungen Metriken zum Monitoren exportieren. Dazu gibt es meist schon fertige Exporter wie etwa Flask, man kann aber auch mit Shell-Scripts Daten zum Export vorbereiten.
Als nächstes gibt es ServiceMonitor. Das ist schon die erste Erweiterung der Kubernetes-API, wenn der Prometheus-Operator im Cluster installiert ist. Lässt sich also leicht mit kubectl api-versions überprüfen. Wie in diesem Beispiel zu sehen ist, der ServiceMonitor ist eine einfache Sache. Er beschreibt den Endpunkt unserer App, wo Metrik-Daten zu erwarten sind.
Auch die Prometheus-Instanz kann wie weiter in dem Beispiel als einfache Ausführung beschrieben werden. Der Apply erstellt einen POD im benannten Namespace mit dem laufenden Prometheus drin. Um diesen erreichbar zu machen, bedarf es eines Service, oder bei der Erreichbarkeit aus dem Internet sogar eines Ingress. Bei Rancher nutzen wir die eingebaute Proxyfunktionalität, brauchen also den Ingress nicht.
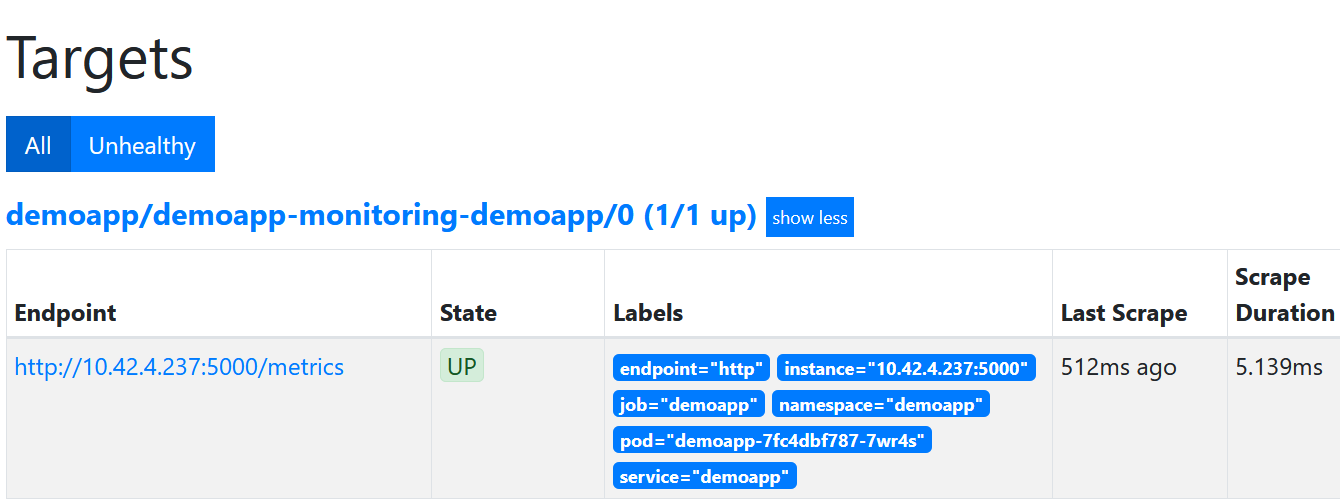
Bei erfolgreicher Verbindung sollte man im Prometheus-UI unter “Service-Discovery” oder auch “Targets” die Instanz der App finden. Ansonsten sollte man schauen, ob der Prometheus wirklich läuft und auch alle Labels richtig gesetzt sind.
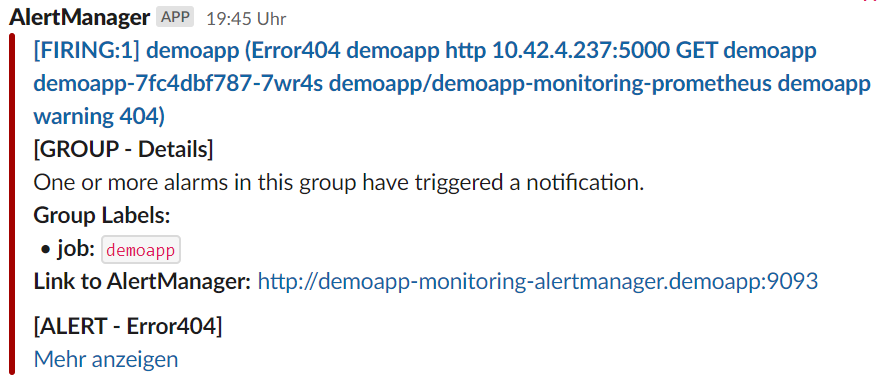
Was beim Prometheus-Operator mitgeliefert wird, ist der Alert-Manager. Dieser hat zwei Hauptfuntionen. Das eine ist der Receiver, das kann ein Slack-Channel sein oder auch E-Mail-Versand ist möglich. Das andere ist der Router. Dort wird entschieden, welche Alarme an welchen Receiver geschickt werden. Haupt-Router/Receiver ist der Alert-Manager selber. Auf dessen Webseite kann man alle Alarme sehen.
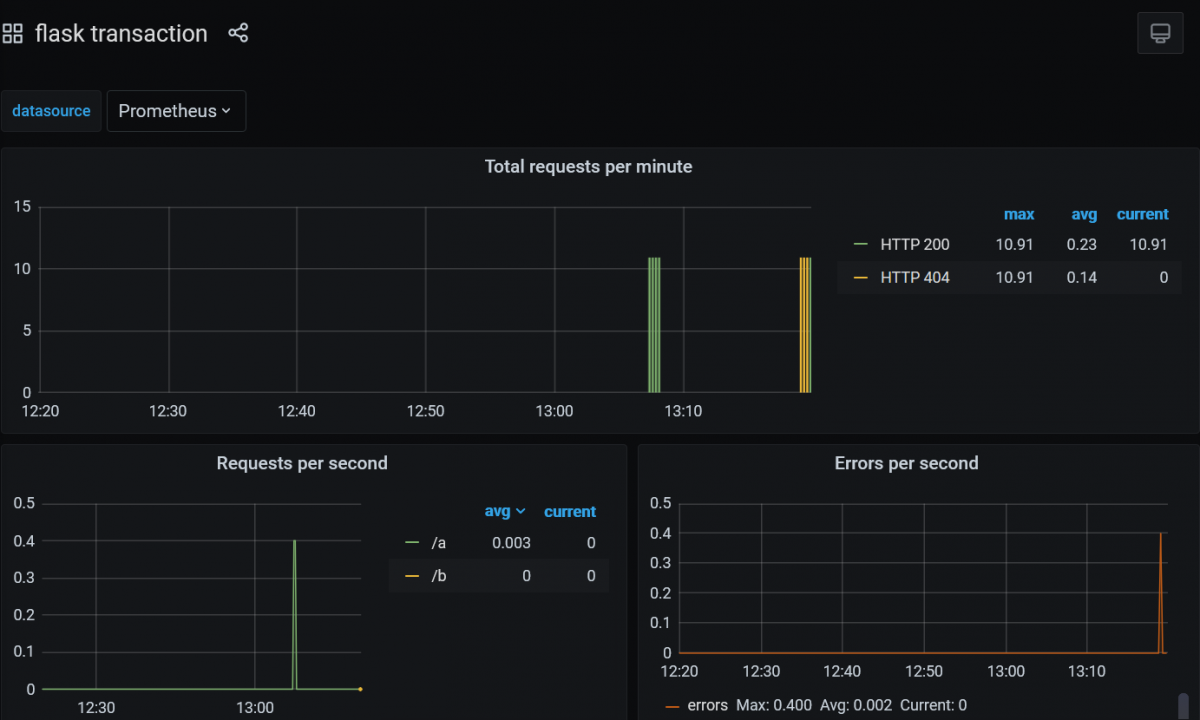
Und was nicht im Prometheus-Operator mitgeliefert wird, ist Grafana. Wenn es dafuer Bedarf gibt, muss eine Instanz eigenständig deployt werden, gerne auch wieder mit der genutzen Proxy-Funktionalität von Rancher.
Wie sieht sowas dann aus bzw. wie kann man sich das ansehen?
Die normale URL zum Monitoring, die auch über das Cluster Explorer Menü verfügbar ist, lautet etwa für Grafana:
https://<rancher-server>/api/v1/namespaces/cattle-monitoring-system/services/http:rancher-monitoring-grafana:80/proxy/
Hier ändern wir einfach die Namen von Namespace und Prometheus-Instanz in der URL im Browser:
https://<rancher-server>/api/v1/namespaces/gnuu/services/http:gnuu-monitoring-grafana:80/proxy/
Andere Dienste wie Prometheus oder Alertmanager sind ebenfalls so erreichbar.
Happy Monitoring
Vollständiges Beispiel (incl. RBAC)
Allgemeines Beispiel für eine App
Hinweis: Die Konfiguratin der Receiver und Routes im Alertmanager ist derzeit noch per Secret gelöst. Hier gibt es bald eigene Resourcen per CRD, die dann direkt beschrieben werden können. Andererseits können diese Konfigurationen auch geheime Daten enthalten, weswegen man vielleicht das Secret beibehalten möchte.