
Das Problem von Automatisierungstools aller Art ist es, dass man zuerst die Tools lernen muss, um sie fuer die eigentliche Aufgabe nutzen zu koennen, etwa eine Applikation oder eine Datenbank zu installieren. Mit der Zeit kuemmert man sich auch um den Lebenszyklus dieser Tools. Neue Releases erscheinen, mit neuen Funktionen und neuer Syntax. Dabei wollte man doch bloss die Applikation installieren?!
Wenn man sich erst einmal auf Kubernetes eingelassen hat, wird man schnell familiaer mit der Syntax der Resource-Dateien, sei es ein Deployment oder ein Pod. Es wird dem Anwender mit kubectl auch leicht gemacht, in welchem Format er seine Ausgaben sehen moechte; json, yaml, plain. Die bereitgestellten Informationen sind immer dieselben: Metadaten, Specs, Status. Wie waere es, wenn Applikationsen jetzt genauso in diesem Format bereitgestellt werden wuerden???. Mit Custom Resource Defintion (CRD) kann man die Kubernetes-API mit seiner eigenen Applikation erweitern. Etwa in der Form: meinedatenbanken.mysql.meinefirma.com. Neben den Metadaten wie Resourcename und Namespace koennte man in Specs Datenbanktyp und Groesse angeben.Willkommen in der wunderbaren Welt von Kubernetes Operator.
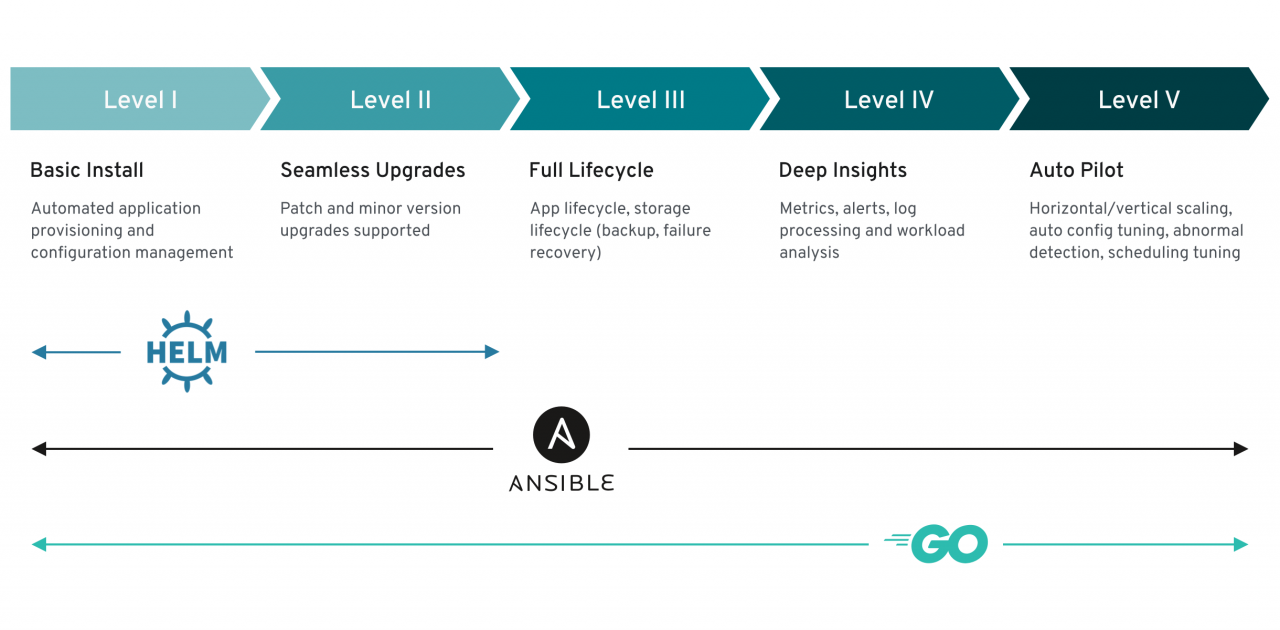
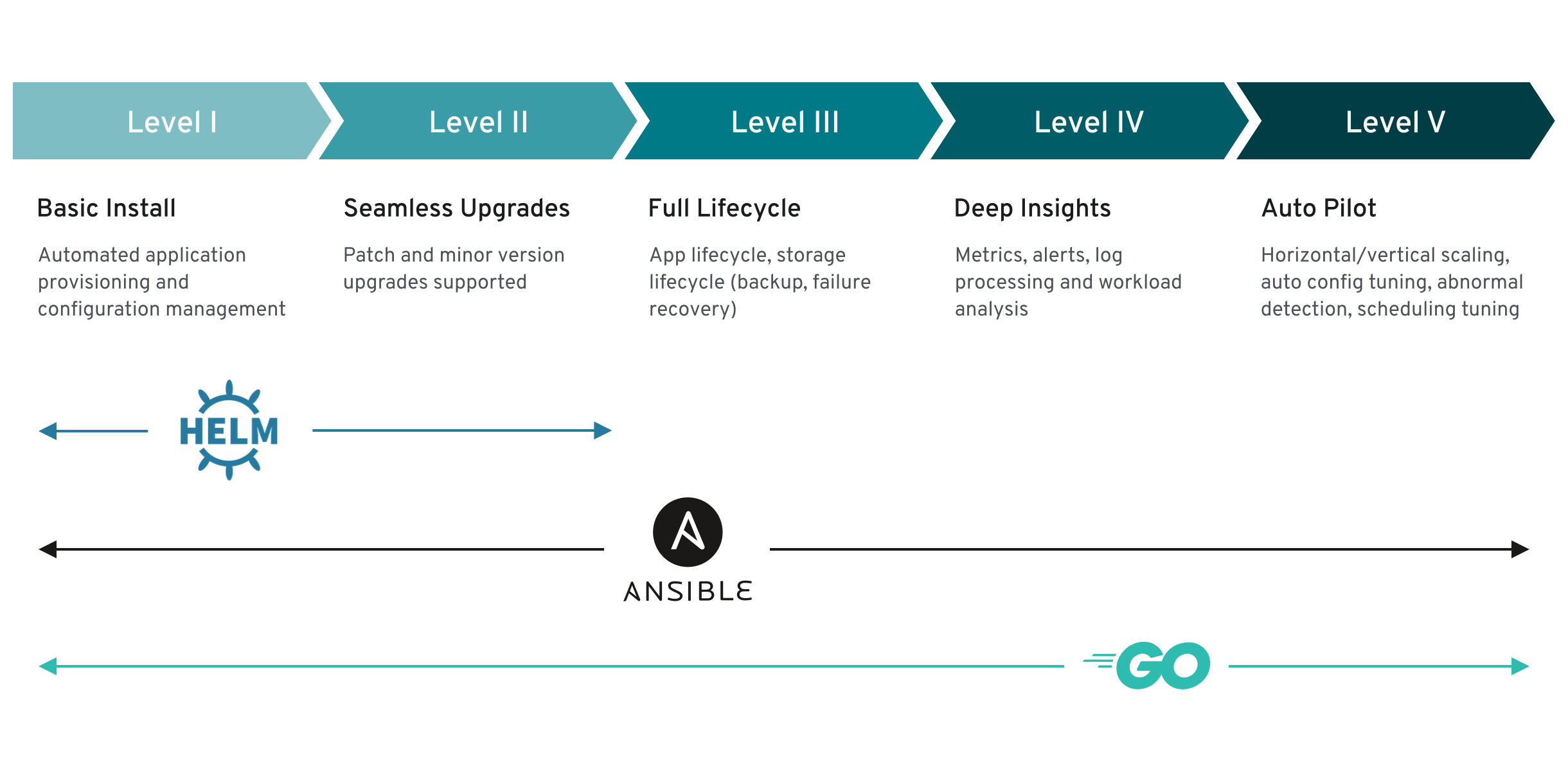
Wenn Applikationsresourcen in Kubernetes als CRD definiert sind, sollte natuerlich auch etwas damit geschehen. Wenn eine MySQL-Datenbank definiert ist, sollte diese am besten auch reell existierbar gemacht werden. Dazu gibt es den Operator, ein Programm in einem POD, der die Logic des CRD praktisch in die Landschaft umsetzt, also eine MySQL-Datenbank mit den definierten Parametern erstellt. Operatoren gibt es in Helm, Ansible und Go-Programmierung. Es gibt aber auch Shell-Operatoren oder einen in Terraform. Fuer die automatisierte Installation und Konfiguration, dem Level 1, sollten alle Operatoren genuegen. Jetzt gehts aber noch weiter.
Im Level 2 soll eine Applikation, wie eine MySQL-Datennbank, upgradefaehig sein. Also ich kann eine Instanz updaten, ohne das es eine Servicebeeintraechtigung gibt. Da haette an beim Shell-Operatore schon etwas Aufwand. Gehen wir gleich zu Level 3 weiter: Hier wird schon der volle Lebenszyklus der Applikation gefordert: Speicherverwaltung, Backup, Wiederherstellung im Fehlerfall. Die meisten Operatoren streichen hier die Segel, weil es schon ein sehr hoher Aufwand ist, von 0 an sowas zu programmieren. Gute gebaute Ansible-Module bekommen sowas hin. Oder Operatoren in Go, die dann einfach fertige Programmbibliotheken wie etwa ein S3-Backend fuer Backups benutzen.
Level 4 haelt Metriken bereit fuer Monitoring und Alarming. Logfileauswertung sind ebenfalls hier zu finden. verbunden mit einer Analyse der Arbeitslast der Applikation. Hier sind normalerweise 3th part tools im Einsatz, aber es ist gefordert, dass die Applikation selber diese Faehigkeiten besitzt.
Es endet dann im Level 5 mit der Auswertung der Daten vom Level zuvor, um die Applikation skalieren zu koennen oder sie im Ausfall zu reparieren. Also die Applikation soll das selber machen. Es gibt gerade mal eine Handvoll davon auf dem Marktplatz operatorhub.io, aber Vorsicht: die Liste ist nicht vollstaendig dort. Auf Github ist auch eine umfangreiche Sammlung gelistet. Die Qualitaet kann man immer nach den Kriterien des Operator Capability Levels ueberpruefen.
Einen etwas tieferen Einstieg mit praktischer Anleitung findet man in ansible-otc-operator. ansible-otc ist ein frueheres Toolset von mir, um mit Ansible-Playbooks Resourcen in der Open Telekom Cloud zu erstellen. Der Ansatz war event-basiert und ist sicherlich heute ueberholt. Ich habe ihn dennoch dazu benutzt, um einen Kubernetes Operator dafuer zu verwenden. Wer sich mit Ansible etwas auskennt, wird sich mit dem dazugehoerigen Operator schnell hereinfinden, zumal das operator-sdk automatisch den Code generieren kann. Mehr dazu auch in meinem Beispiel zu ansible-otc-operator. Viel Spass bei der Lektuere und beim Ausprobieren.
{kind=link}