
The problem with all kinds of automation tools is that you first have to learn the tools in order to be able to use them for the actual task, such as installing an application or a database. Over the time, you also take care of the life cycle of these tools. New releases appear, with new functions and new syntax. Remember: You just wanted to install the application ?!
Once you get involved with Kubernetes, you quickly become familiar with the syntax of the resource files, like Deployment or a Pod . With kubectl it is also made easy for the user in which format he would like to see his output; json, yaml, plain. The information provided is always the same: metadata, specs, status. How would it be if applications were now provided in the same format ??? . With Custom Resource Defintion ( CRD) you can extend the Kubernetes API with your own application. For example in the form: mydatabase.mysql.mycompany.com. In addition to the metadata such as resource name and namespace, you could specify the database type and size in Specs. Welcome to the wonderful world of Kubernetes Operator .
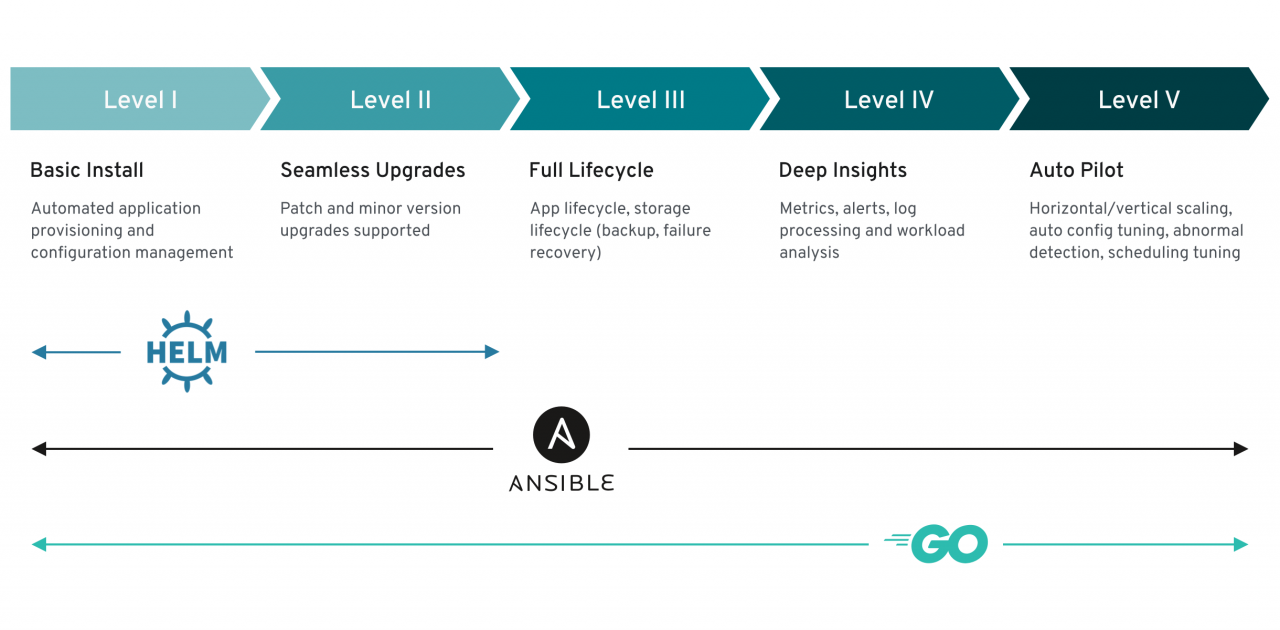
If application resources are defined as CRD in Kubernetes, something should of course also be done with it. If a MySQL database is defined, it should best be made real. There is also the Operator, a program in a POD, which practically translates the logic of the CRD into the landscape, i.e. creates a MySQL database with the defined parameters. There are operators in Helm, Ansible and Go programming . However, there are also shell operators or one in Terraform . All operators should be sufficient for automated installation and configuration, level 1. But now it goes on.
In level 2, an application, such as a MySQL database, should be upgradeable. So I can update an instance without there being a service impairment. There would be some effort involved with the shell operator. Let’s go straight to Level 3: The full life cycle of the application is already required: storage management, backup, recovery in the event of an error. Most Operators are doing away with the sails here, because programming something like this from zero onwards is very time-consuming. Well built Ansible modules can do that. Or operators in Go, on behalf of existing program libraries such as an S3 backend for backups.
Level 4 has metrics ready for monitoring and alarming. Log file evaluation can also be found here, combined with an analysis of the workload of the application. 3th party tools are usually used here, but it is required that the application itself has these capabilities.
It ends in level 5 with the evaluation of the data from the previous level in order to be able to scale the application or to repair it in the event of a failure. So the application should do it itself. There are just a handful of them on the operatorhub.io marketplace, but be careful: the list is not exhaustive there. There is also a extensive collection listed on Github. The quality can always be checked according to the criteria of the Operator Capability Level .
A somewhat deeper introduction with practical instructions can be found in ansible-otc-operator . ansible-otc is an earlier toolset by me to create resources in the Open Telekom Cloud with Ansible-Playbooks. The approach was event-based and is certainly outdated today. I still used it to build a Kubernetes Operator for that. If you are familiar with Ansible, you will quickly find your way around with the associated operator, especially since the operator-sdk can automatically generate the code. More on this in my example on ansible-otc-operator. Enjoy the reading and try it out.
{kind=link}