
Neues Jahr, neues Projekt, könnte man sagen. Aber dieses begann am Ende des letzten, ist dennoch ein guter Start ins Neue.
Die Verwendung von Docker-Containern in Kubernetes ist eine bekannte Notwendigkeit,
auch wenn dockerd mittlerweile durch containerd ersetzt wurde.
Das Vorgehen ist auch weit etabliert: Es gibt ein Dockerfile mit einer
Definition zu einem Basis-Image oder man startet From: scratch und dann bringt man die Programmlogik rein und installiert
Pakete.
Das Problem dabei ist, im Resultat weiss man nicht genau, was in dem Docker-Container drin ist, wenn man ihn nicht selber erstellt hat. Dieses Problem hat mittlerweile einen Namen bekommen: Supply Chain Attack. Es ist nicht klar, was der Container alles kann und welche Backdoors vielleicht eingebaut worden sind.
Praktisches Beispiel zur Hand: https://hub.docker.com/r/gnuu/busybox - ein Container aus unserem Gnuu Projekt, was wir im Projekt selber vielleicht 100 mal runtergeladen haben. Docker Hub weist aber Downloadraten weit über 10.000 auf! Selbst https://hub.docker.com/r/gnuu/postfix hat mehr als 2500 Downloads, obwohl in der Beschreibung steht, dass dieser Container ein spezielles Konstrukt ist und nur unter bestimmten Konfigurationen funktioniert. Hat jeder diese Beschreibung gelesen? Hat jeder das referenzierte Dockerfile auf Github und die Build-Pipeline überprüft? Wahrscheinlich nicht. Der Name ist cool, ich brauche ein Busybox-Image, und schon hat man sich irgendein Dreckszeug eingefangen.
Die Lösung des Problems des Unbekannten Containers existiert schon sehr lange: Docker Content Trust. Die Container werden mit einem Schlüssel signiert und die Signaturen in einem Notariat abgelegt. Das Verfahren hatte seit seiner Erfindung schon starke Schlagseite. Die Signaturen waren nicht geschützt - ja, jedermann konnte sie sogar einfach löschen. Ausserdem war es nicht bis zu Ende gedacht, denn die Container mit den Signaturen mussten vor der Benutzung ja mal irgendwie verifiziert werden. Dazu gab es keine Software.
Zum Glück hat die Containersicherheit in den letzten Jahren stark an Bedeutung gewonnen. Nicht nur, dass Notary V2 ins Leben gerufen wurde, es entwickelten sich weitere Standards um den OCI Layer, die es ermöglichten, weitere Informationen zum Docker-Container am selben Platz zu speichern wie etwa seine Signaturen
Cosign Sigstore hat sich als neuer Standard für Container Signierung etabliert. Der ganze Prozess aus Signierung und Verifizierung besteht aus 3 Kommandos:
$ cosign generate-key-pair
$ cosign sign --key cosign.key mtr.devops.telekom.de/eumel8/test1:signed
$ cosign verify --key cosign.pub mtr.devops.telekom.de/eumel8/test1:signed
Fertig!
Kubernetes Admission Controller sind Werkzeuge aus dem Zugriffs- und Authorisierungsmanagement, die Aufgaben im Cluster sortieren und lenken. Verschiedene Admission Controller benutzen wir vielleicht schon, ohne es zu wissen: ServiceAccounts, PodSecurity, PodSecurityPolicy, Priority, ResourceQuota - alles Admission Controller.
Man unterscheidet ValidationWebhookConfiguration, um Sachen zu validieren. Und MutatingWebhookConfiguration, um Sachen auch zu verändern.
Im Cert Manager gibt es zum Beispiel beides: Den ValidationWebhook, um Zertfikate und deren Gültigkeit zu verifizieren und MutationWebhook, um neue auszustellen.
Schematische Darstellung eines POD-Lebenszyklus mit Admission Controller:
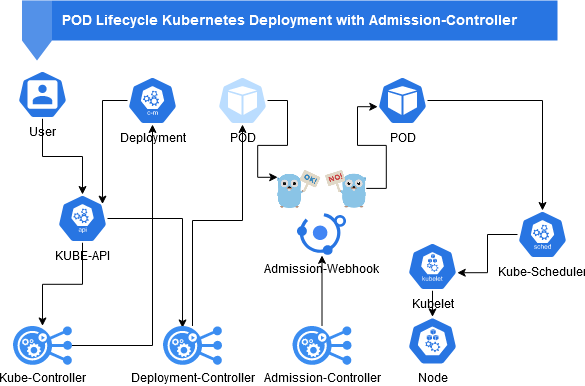
Die Überprüfung von Signaturen von Containern ist eine prädistinierte Aufgabe für einen Admission Controller. Deswegen kommt er auch in zahlreichen Tools zum Einsatz:
Ein Admission Controller, der einen ganzen Hub von Plugins für einen Policy Server bereithält. Einer davon ist zur Verifizierung von Images zuständig. Der User kann Policies erstellen, die dann von dem Policy Server durch eine neue Instanz umgesetzt werden. Da ist dann auch der Knackpunkt: ist eine Policy fehlerhaft, funktioniert cluster-weit der ganze Updateprozess nicht mehr. Ausserdem hat man ganz schönen Overhead, wenn man nur dieses eine Plugin nutzen will. Und noch ein Manko: diese Policies haben wieder ein bestimmtes Mime-Format, die nicht von allen Registries unterstützt werden.
Dieser versucht die Interaktionen mit Usern völlig zu umgehen, indem er einfach nur ClusterImagePolicy anbietet, die dann nur von einem cluster-admin verwaltet werden dürfen. Über eine namespaced Lösung denkt man noch nach.
Auch ein Werkzeug mit vielen Policy-Plugins. Eines ist zur Verifizierung von Images. Bereitgestellt werden diese in ClusterPolicy, auch eine nicht-namespaced Resource. Jetzt könnte man darauf kommen, dass jeder User sein eigenes Tool im shared Cluster installiert. Aber das funktioniert natürlich nicht, wenn zentrale Resourcen wie ClusterRoles oder besagte WebHooks angelegt werden. Man könnte das alles ausnanderfieseln, die Webhooks noch mit Namespace-Selektoren versehen (technisch wäre das alles drin), aber wer will sowas verwalten.
Bei diesem Werkzeug werden die Policies im Helm-Chart mit installiert. In der Single-Instanz sehr praktisch, aber die zweite Installation im selben Cluster scheitert schon an gemeinsam genutzen Resourcen (siehe oben).
Open Policy Agent(OPA) ist auch eher eine Werkzeugsammlung, in der ich mit einer Script-Sprache Policies selbst entwerfen kann. Für Cosign gibt es zwar schon einen Provider, aber der überprüft nur, ob es eine Container-Signatur gibt und nicht ob diese gültig ist. Aber an diesem könnte man anknüpfen, wenn man sich mit dieser Scriptsprache etwas beschäftigt und solche Anwendungsfälle wie Signatur-Speicherort und private Images beachtet.
An dieser Stelle beginnt die Geschichte unseres eigenen Admission Controllers. Dieser beginnt mit einer Konfiguration:
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingWebhookConfiguration
metadata:
name: cosignwebhook
webhooks:
- admissionReviewVersions:
- v1
name: cosignwebhook.caas.telekom.de
namespaceSelector:
matchExpressions:
- key: kubernetes.io/metadata.name
operator: NotIn
values: ["cosignwebhook", "kube-system", "cattle-system", "default"]
clientConfig:
service:
name: cosignwebhook
namespace: cosignwebhook
path: "/validate"
caBundle: "LS0..."
rules:
- operations: ["CREATE","UPDATE"]
apiGroups: [""]
apiVersions: ["v1"]
resources: ["pods"]
failurePolicy: Fail
sideEffects: None
Wir schauen also wie in dem Schaubild oben nach Events im Cluster die PODs erstellen oder aktualisieren möchten.
Diese Information wird an einen Service cosignwebhook im Namespace cosignwebhook gesendet. Einige Namespaces sind
von der Validierung ausgenommen, wie etwa der Controller selber und einige System-Namespaces.
Im cosignwebook Namespace haben wir also einen Service und einen dahinterliegenden Pod, bereitgestellt durch ein
Deployment mit dem eigentlichen Admission-Controller.
Es ist ein Webservice, also brauchen wir erstmal einen Webserver, der auf diese Anfragen antwortet:
func (cs *CosignServerHandler) serve(w http.ResponseWriter, r *http.Request) {
var body []byte
if r.Body != nil {
if data, err := io.ReadAll(r.Body); err == nil {
body = data
}
}
if len(body) == 0 {
glog.Error("empty body")
http.Error(w, "empty body", http.StatusBadRequest)
return
}
if r.URL.Path != "/validate" {
glog.Error("no validate")
http.Error(w, "no validate", http.StatusBadRequest)
return
}
Ziel-URL ist also /validate. Dort soll dann etwas passieren.
Das Objekt ist AdmissionReview (siehe API-Beschreibung und dort haben wir ein Pod-Objekt zur Überprüfung eingebettet:
arRequest := v1.AdmissionReview{}
if err := json.Unmarshal(body, &arRequest); err != nil {
glog.Error("incorrect body")
http.Error(w, "incorrect body", http.StatusBadRequest)
return
}
raw := arRequest.Request.Object.Raw
pod := corev1.Pod{}
if err := json.Unmarshal(raw, &pod); err != nil {
glog.Error("error deserializing pod")
return
}
Zur Signatur-Überprüfung brauchen wir den Cosign-Public-Key. Der ist im POD in einer Environment-Variable abgelegt:
pubKey := ""
for i := 0; i < len(pod.Spec.Containers[0].Env); i++ {
value := pod.Spec.Containers[0].Env[i].Value
if pod.Spec.Containers[0].Env[i].Name == cosignEnvVar {
pubKey = value
}
}
Dann brauchen wir den Image-Namen:
image := pod.Spec.Containers[0].Image
refImage, err := name.ParseReference(image)
Das Image könnte nicht-öffentlich sein. Dann brauchen wir die ImagePullSecrets:
imagePullSecrets := make([]string, 0, len(pod.Spec.ImagePullSecrets))
for _, s := range pod.Spec.ImagePullSecrets {
imagePullSecrets = append(imagePullSecrets, s.Name)
}
opt := k8schain.Options{
Namespace: pod.Namespace,
ServiceAccountName: pod.Spec.ServiceAccountName,
ImagePullSecrets: imagePullSecrets,
}
Das Herzstück sind dann bloss noch ein paar Zeilen, die die Original-Cosign-Routine zum Verifizieren von Signaturen verwendet. k8schain ist eine nette Bibliothek von Google, die sich um das Zusammensammeln der Secrets und das Einloggen in der Container-Registry kümmert, damit wir dort Zugriff auf das Image und deren Signatur haben:
kc, err := k8schain.NewInCluster(context.Background(), opt)
remoteOpts := []ociremote.Option{ociremote.WithRemoteOptions(remote.WithAuthFromKeychain(kc))}
_, _, err = cosign.VerifyImageSignatures(
context.Background(),
refImage,
&cosign.CheckOpts{
RegistryClientOpts: remoteOpts,
SigVerifier: cosignLoadKey,
})
Das Ergebnis ist etwas komisch. Wenn kein Fehler zurückkommt, ist alles in Ordnung und das Image verifiziert.
Der Admission-Controller gibt einen Admission-Response Success zurück:
v1.AdmissionReview{
TypeMeta: metav1.TypeMeta{
Kind: admissionKind,
APIVersion: admissionApi,
},
Response: &v1.AdmissionResponse{
Allowed: admissionPermissions,
UID: ar.Request.UID,
Result: &metav1.Status{
Status: admissionStatus,
Message: admissionMessage,
Code: admissionCode,
},
},
Die Container-Signatur wurde erfolgreich überprüft. Die Anfrage wird an den Scheduler weitergeleitet, der den POD letztlich auf einen Node verteilt und der Kubelet den POD überwacht und startet.
Interessiert an den Details? Cosign Webhook ist auf Github verfügbar, zusammen mit Installationsanleitungen und Downloadmöglichkeiten.
Happy Secure Containering!