
At first a recap: What is a Operator?
With Kubernetes Operator you can extend the Kubernetes API with a function that it doesn’t have before.
For example: A refrigerator


Kind: Refrigerator
Specs:
Color: string
Height: string
Width: string
Weight: string
Shelfs: int
As you can see, we can specify the color of the refrigerator, the size, and how many shelfs are into. At the end, your Kubernetes Cluster can manage refrigerators. Of course, there is no item in your data center, but maybe a manufacture can handle this requests, if the machines are connected to the cluster.

Another Example: RDS

Kind: Rds
Specs:
Datastoretyp: string
Datastoreversion: string
Flavorref: string
Port: int
Volumesize: int
Volumetype: string
The same thing. The RDS has specifications like Dataastoretyp, Datastoreversion, Port, and so on. How comes this description in the cluster? There is the possibility to extend Kubernetes API:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: rdss.otc.mcsps.de
finalizers:
- otc.mcsps.de/rds
spec:
group: otc.mcsps.de
names:
kind: Rds
listKind: RdsList
plural: rdss
singular: rds
shortNames:
- rds
scope: Namespaced
versions:
- name: v1alpha1
You are free to invent a domain/group name, and resource name, to your first API version v1alpha1
In the Operator you need later the same specification, so Kubernetes knows this resources and can react on it, e.g, kubectl get rds
Let’s have a deeper look into the Operator after the design of CRD and API extension. The core component of the Operator is the Controller. The controller is a stupid thing. He knows only three commands:
That’s it. If you explore the Kubernetes source code you will find a lot of controller. E.g. a deployment controller, which can handle PODs. As this standard tool in Kubernetes, the controller has some additional adding, which is shipped in:
In lazy mode, we can copy each kind of controller, or use the https://github.com/kubernetes/sample-controller.
Apart from this comes now some super-unique, because until this point we have a normal Kubernetes controller which follows the behaviour of Kubernetes resources. To make things really happen, I’ve wrote 1000 lines of code. It’s simple to follow the mantra: Create, Update, Delete a RDS instance on OTC.
At first we need a connect to the cloud. Luckily there is a Gophercloud Fork, special adapted for OTC - the Gophertelekomcloud. That’s an SDK, which translated Cloud API calls to Go and provides function to manage cloud resources. You should always check, if something exists, which is the state, it’s under active maintenance and how is the coverage on tests and features.
I started small with 150 lines of code to list ECS instances on OTC. A good example to get familiar with the SDK. Later I’ve wrote the next snippet to create a RDS based on a yaml file and re-used the code in a bigger context of an Operator. Sometimes things are missing in the SDK. Like the Point in Time Recovery for RDS. I provided this feature in a PR and got connected to the core developer and extended programming like unit tests. This is also a good example how to use the SDK function. Beside unit tests there are acceptance tests on real resources and not only dummies.
It’s a highlight to put all this things together and create your first RDS instance in Kubernetes:
Additional features are coming fast, especially sync the RDS status in the cloud with the status of the RDS resource in Kubernetes. Ground-making, because we will need this feature later very often. Resize resources is also a feature request by the Operator approach, so it’s easy to implement a manual flavour change by the user by changing the RDS spec.
apiVersion: otc.mcsps.de/v1alpha1
kind: Rds
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"otc.mcsps.de/v1alpha1","kind":"Rds","metadata":{"annotations":{},"name":"my-rds-single","namespace":"rds1"},"spec":{"password":"A12345678+","securitygroup":"golang","subnet":"frank-test","vpc":"frank-test"}}
creationTimestamp: "2022-05-26T16:32:39Z"
generation: 3
name: my-rds-single
namespace: rds1
resourceVersion: "231728197"
uid: ffdd07fa-6e6f-4462-9c52-6369033d6701
spec:
availabilityzone: eu-de-01
backupkeepdays: 12
backuprestoretime: ""
backupstarttime: 01:00-02:00
datastoretype: MySQL
datastoreversion: "8.0"
endpoint: ""
flavorref: rds.mysql.c2.medium
password: xxxxxxxxxx
port: "3306"
region: eu-de
securitygroup: golang
subnet: frank-test
volumesize: 40
volumetype: COMMON
vpc: frank-test
status:
autopilot: false
id: b63d19cfad814cc7a77c73c3092c28bfin01
ip: 10.9.3.78
logs: false
reboot: false
status: BUILD
Let’s have a look at the Operator Level Approach:
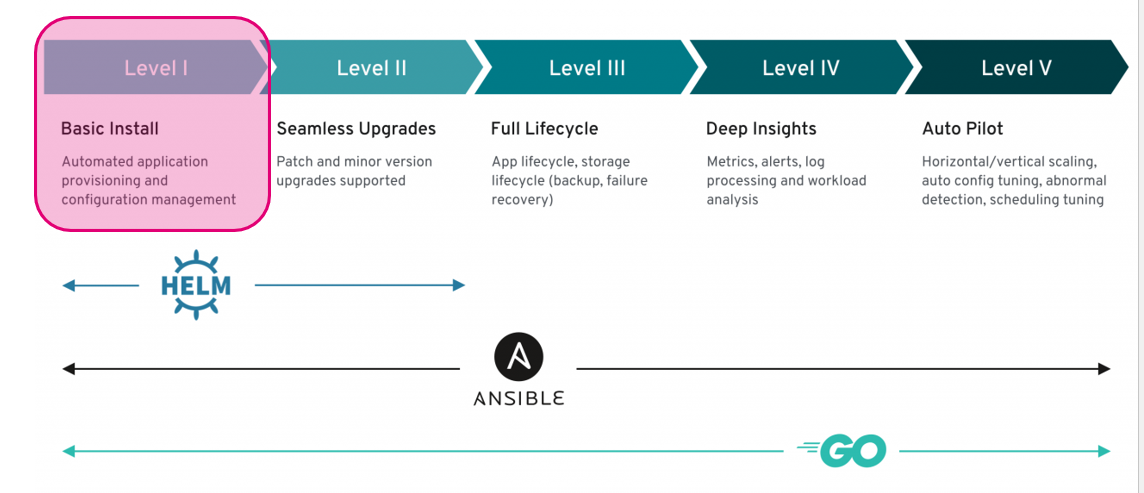
While creating a RDS we are on Level 1 of the Operator Level Approach. If we can choose a MySQL version and upgrade also the flavour, that’s an extended configuration management. Bump to level 2.
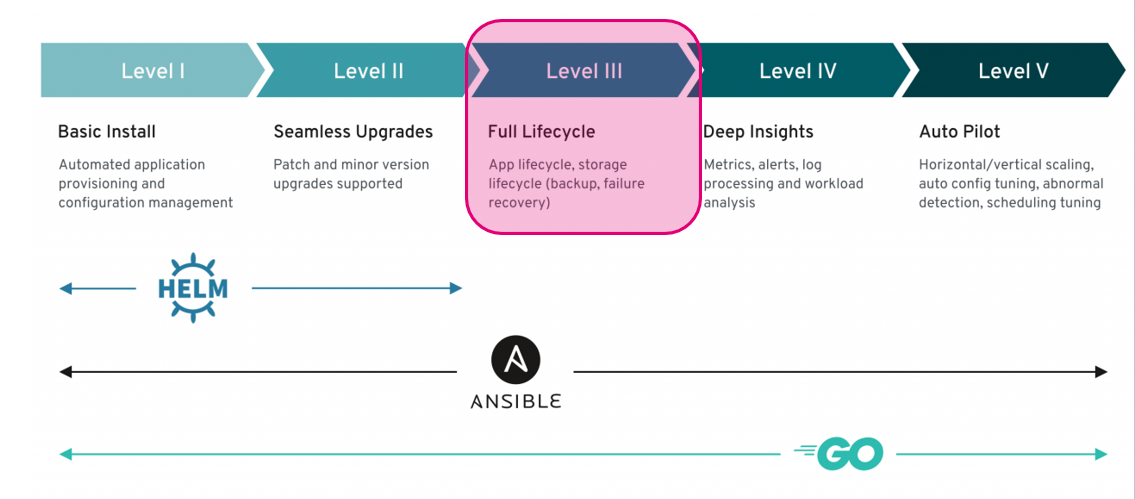
Level 3 includes the application live cycle inclusive backups. Backups are automatically generated by the cloud. But we can implement a restore feature based on our brand-new Point in Time Recovery function from the SDK:
// Restore backup PITR
if newRds.Spec.Backuprestoretime != "" { // 2020-04-04T22:08:41+00:00
c.logger.Debug("rdsUpdate: restore instance")
eventMsg := fmt.Sprint("This instance is restoring to ", newRds.Spec.Backuprestoretime)
c.recorder.Eventf(newRds, rdsv1alpha1.EventTypeNormal, "Update", string(eventMsg))
rdsRestoredate, err := time.Parse(time.RFC3339, newRds.Spec.Backuprestoretime)
if err != nil {
err := fmt.Errorf("can't parse rds restore time: %v", err)
return err
}
newRds.Spec.Backuprestoretime = ""
if err := c.UpdateStatus(ctx, newRds); err != nil {
err := fmt.Errorf("error update rds status: %v", err)
return err
}
rdsRestoretime := rdsRestoredate.UnixMilli()
restoreOpts := backups.RestorePITROpts{
Source: backups.Source{
InstanceID: newRds.Status.Id,
RestoreTime: rdsRestoretime,
Type: "timestamp",
},
Target: backups.Target{
InstanceID: newRds.Status.Id,
},
}
restoreResult := backups.RestorePITR(client, restoreOpts)
if restoreResult.Err != nil {
err := fmt.Errorf("rds restore failed: %v", restoreResult.Err)
return err
}
In level 4 we have to care about monitoring, metrics, and logs. Most of them are already provides by OTC. Questionably is only: how to provide 100+ lines of log of one RDS instance to the user, without mess up the etcd, because that’s the thing where the cluster stores all kind of information.
if newRds.Status.Logs {
c.logger.Debug("rdsUpdate: instance errorlogs")
newRds.Status.Logs = false
if err := c.UpdateStatus(ctx, newRds); err != nil {
err := fmt.Errorf("error update rds status: %v", err)
return err
}
c.recorder.Eventf(newRds, rdsv1alpha1.EventTypeNormal, "Update", "This instance fetch logs.")
opts, err := openstack.AuthOptionsFromEnv()
if err != nil {
err := fmt.Errorf("error getting auth from env in logfetch: %v", err)
return err
}
provider, err := openstack.AuthenticatedClient(opts)
if err != nil {
err := fmt.Errorf("error building auth client: %v", err)
return err
}
client, _ := openstack.NewIdentityV3(provider, golangsdk.EndpointOpts{})
if os.Getenv("OS_PROJEKT_ID") != "" {
projectID = os.Getenv("OS_PROJECT_ID")
}
authOptions := tokens.AuthOptions{
IdentityEndpoint: opts.IdentityEndpoint,
Username: opts.Username,
Password: opts.Password,
Scope: tokens.Scope{ProjectID: projectID},
DomainName: opts.DomainName,
}
token, err := tokens.Create(client, &authOptions).ExtractToken()
if err != nil {
err := fmt.Errorf("error getting token in logfetch: %v", err)
return err
}
job := createJob(newRds, opts.IdentityEndpoint, token.ID)
For this feature we spawn a K8s job, use another small Go Programm to fetch the RDS logs from OTC API and put this to the job output, where the user can read the information. The fun thing on this code part: To get API connection to OTC you need credentials. The core credentials for the operator would be stored in this job in the user namespace. To prevent this, we create a token for the time where the job is running. After return, the token will expire. The user has the token, but it’s still invalid.
Kings class are now: Autopilot:
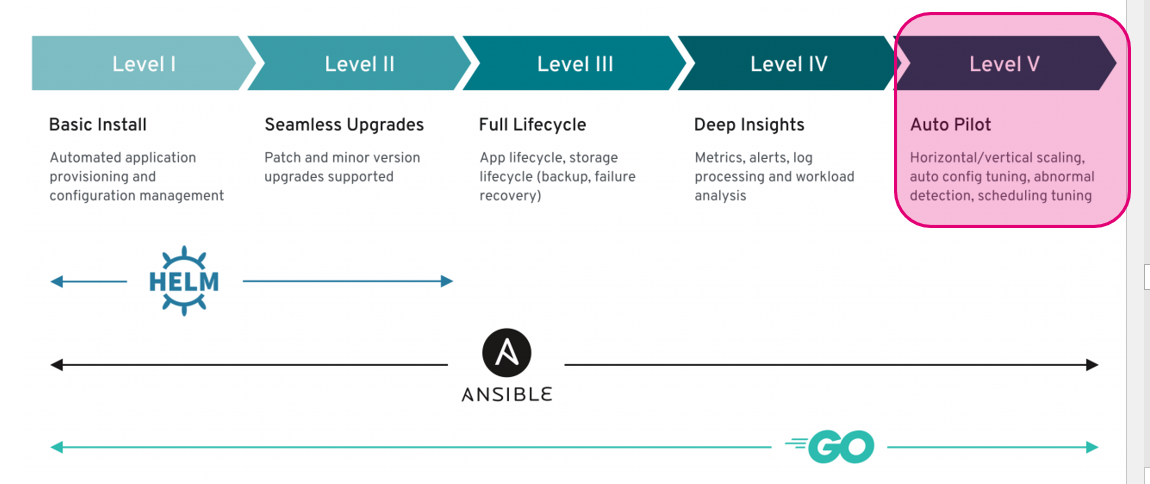
To get this feature, we use cloud monitoring & metrics and interact on it in the Operator:
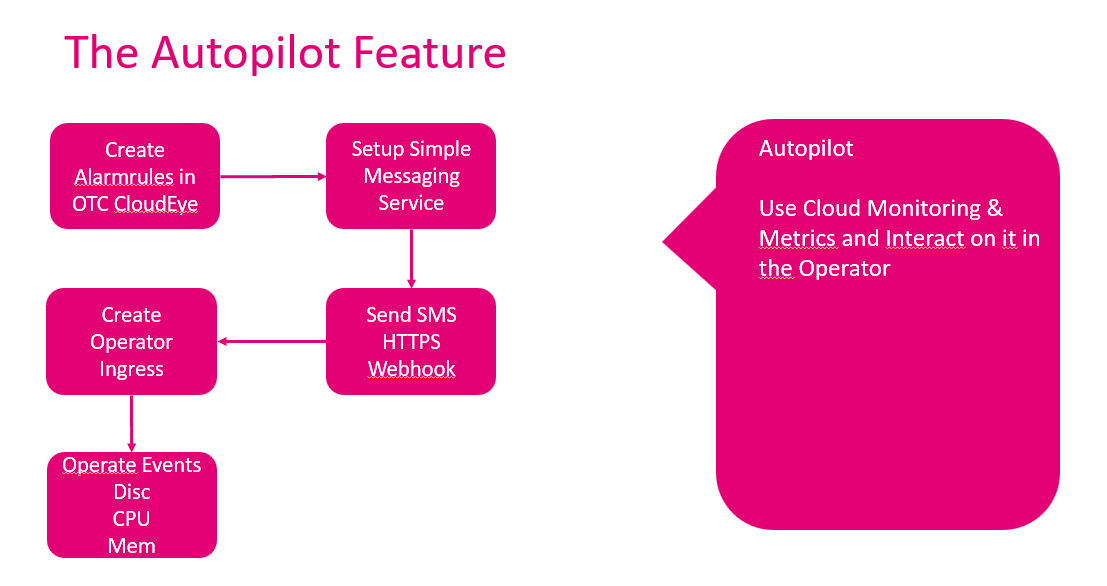
Alarm rules will created after setup Ingress and SMN:
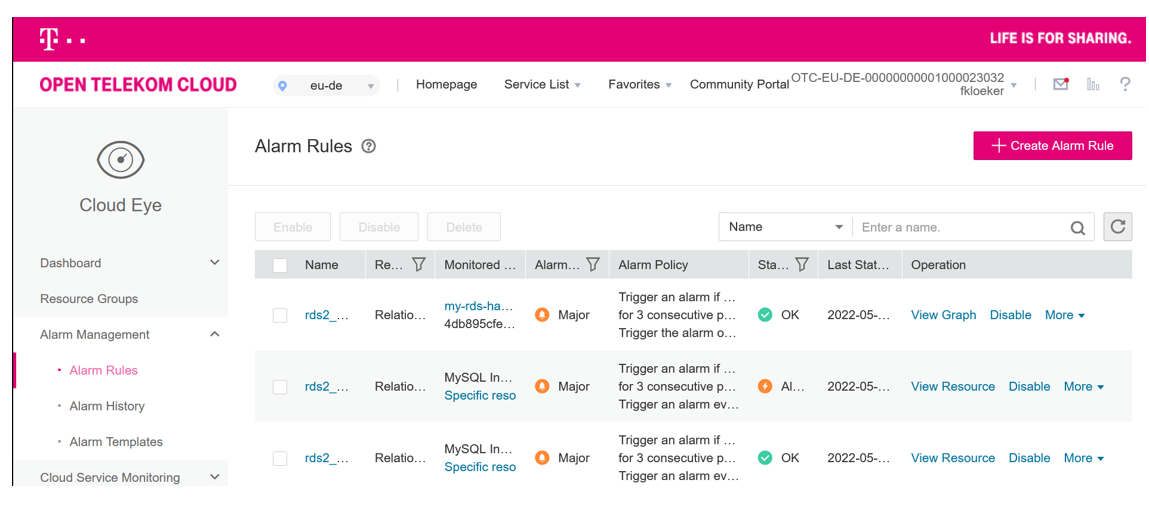
Now we can interact on alarms. Storage alarms are pretty simple. We increase the storage of the RDS plus 10 GB until the alarm is gone. (Remark: repeatable alarm was not supported by SDK, needs also to extend.
And the next riddle: find the next available flavour if cpu or memory alarm occurs.
switch raisetype {
case "cpu":
for _, rds := range rdsFlavors {
for n, az := range rds.AzStatus {
if n == az1 && az == "normal" {
for l, az := range rds.AzStatus {
if az2 == "" || l == az2 && az == "normal" {
if strings.HasSuffix(newRds.Spec.Flavorref, ".ha") && strings.HasSuffix(rds.SpecCode, ".ha") && rds.VCPUs > curCpu {
iCpu, _ := strconv.Atoi(rds.VCPUs)
posflavor = append(posflavor, struct {
VCPUs int
RAM int
Spec string
}{iCpu, rds.RAM, rds.SpecCode})
}
if !strings.HasSuffix(newRds.Spec.Flavorref, ".ha") && !strings.HasSuffix(rds.SpecCode, ".rr") && !strings.HasSuffix(rds.SpecCode, ".ha") {
iCpu, _ := strconv.Atoi(rds.VCPUs)
posflavor = append(posflavor, struct {
VCPUs int
RAM int
Spec string
}{iCpu, rds.RAM, rds.SpecCode})
}
}
}
}
}
}
sort.Slice(posflavor, func(i, j int) bool {
return posflavor[i].VCPUs < posflavor[j].VCPUs
})
if len(posflavor) > 0 {
return posflavor[0].Spec, nil
}
The special: not all flavours are available on all availability zones, so this needs to check also. And of course, sometimes we reached the biggest flavour and can not scale up anymore.
Another feature is the user management. Invent a structure on RDS spec how to describe database schema, user, and permissions:
spec:
databases:
- project1
- project2
users:
- host: 10.9.3.%
name: app1
password: app1+Mond
privileges:
- GRANT ALL ON project1.* TO 'app1'@'10.9.3.%'
- GRANT SELECT ON project2.* TO 'app1'@'10.9.3.%'
- host: 10.9.3.%
name: app2
password: app2+Tues
privileges:
- GRANT SELECT ON project2.* TO 'app2'@'10.9.3.%'
The password handling is not the best: User passwords are visible in Spec, sometimes also the root password (will be deleted after successful creating of the RDS instance, where the provides password is applied).
Instead we have an extra extra feature:
func (c *Controller) rdsDelete(client *golangsdk.ServiceClient, newRds *rdsv1alpha1.Rds) error {
c.logger.Debug("rdsDelete ", newRds.Name)
if newRds.Status.Id != "" {
c.recorder.Eventf(newRds, rdsv1alpha1.EventTypeNormal, "Create", "This instance is deleting.")
// make a backup before instance deleting
backuptime := strconv.FormatInt(time.Now().Unix(), 10)
backupOpts := backups.CreateOpts{
InstanceID: newRds.Status.Id,
Name: newRds.Namespace + "_" + newRds.Name + "_" + backuptime,
Description: "RDS Operator Last Backup",
}
backupResponse, err := backups.Create(client, backupOpts).Extract()
if err != nil {
err := fmt.Errorf("error creating rds backup before instance deleting: %v", err)
return err
}
// backupResponse, err := backupResult.Extract()
err = backups.WaitForBackup(client, backupOpts.InstanceID, backupResponse.ID, backups.StatusCompleted)
//backupList := backups.List(client, &backups.ListOpts{BackupID: backupResponse.ID})
//fmt.Println("BACKUP JOB: ", backupList)
if err != nil {
err := fmt.Errorf("error wait for rds backup before instance deleting: %v", err)
return err
}
If the user deleted the RDS instance in the cluster, a backup will created, after delete the RDS instance in the cloud. I think this can fill up your tip box.
That’s all for the Level 5 Operator. You can find all the things on Github. Github is really helpful because bots are scanning your code and give advises for security incidents or update
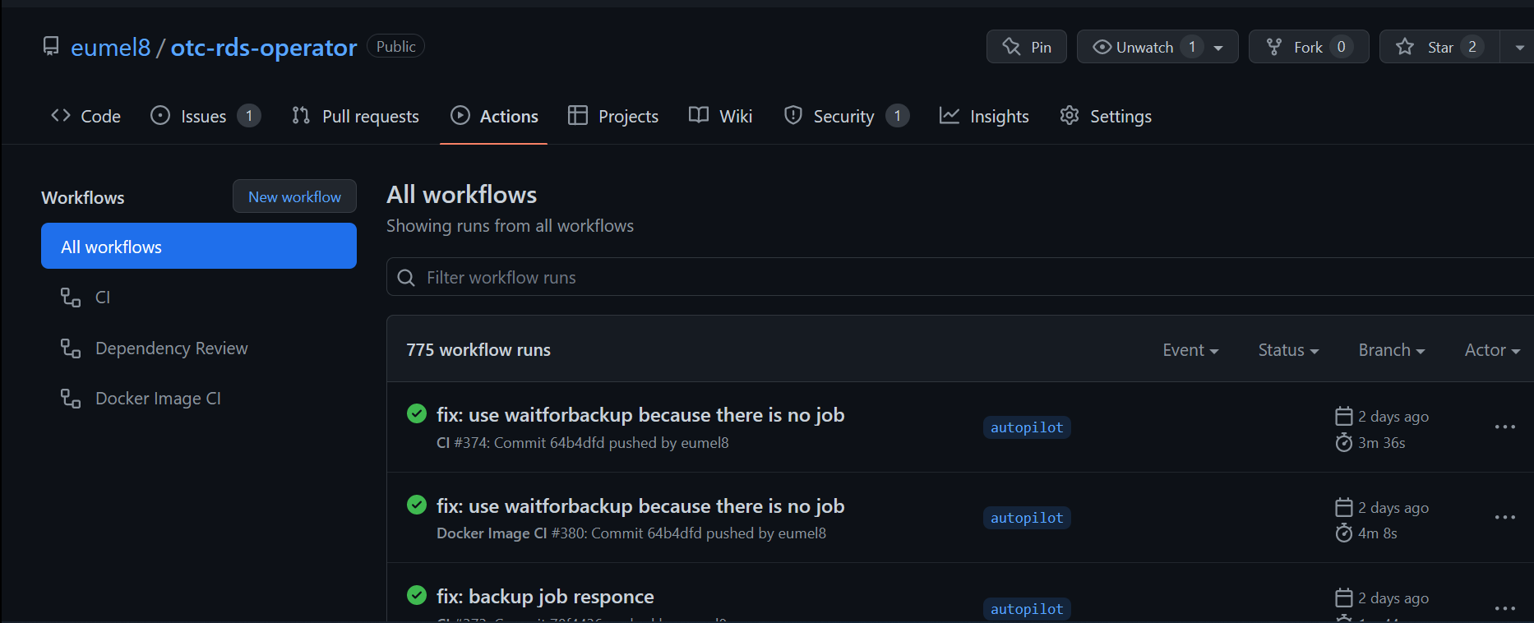
Also Github Action is very good, to compile Go code, build an container and push them to the Github Registry.
The usual features like description of the repo, set search tags and provide release information gives a good overview of the project. But don’t forget some documentation. Testing is still an open point.
Also usage of Microsoft Visual Studio Code can be helpful while programming with the Golang extensions.
My Key Takeaways: