
IPv6 Grundlagen
Es begab sich zu einer Zeit, irgendwann am Ende des letzten Jahrtausends, und es machte sich eine grosse Unruhe breit: Oooh, das Internet ist voll! Die IP-Adressen sind alle! Eine IP-Adresse brauch jedes Netzwerkgeraet im Internet, um kommunizieren zu koennen. Im Protokoll 0 (IP oder auch IPv4) besteht die IP aus 4 Oktets und bildet eine 32-bit-Adresse. Sie faengt bei 0.0.0.0 an und hoert bei 255.255.255.255 auf. Das sind knapp 4 Milliarden Adressen, abzueglich einiger reservierter Adressbereiche. Nun, nach 20 Jahren sind sie immer noch nicht alle. Seit 20 Jahren gibt es auch IPv6. Hier werden jetzt 128-bit-Adressen vergeben. Die somit verfuegbaren IP-Adressen sind nicht mehr 2 hoch 32, sondern 2 hoch 128 - eine immens lange Zahl. Und genauso lang sind auch die Adressen selber, z.B. 2003:e9:f74a:ecf8:8088:5353:3838:eaa1. Das ist eine IP-Adresse. Der Prefix dazu ist /128 (vgl. IPv4: /32). Ein weiterer ueblicher Prefix ist /64. Unser Provider stellt uns zum Beispiel als oeffentliche Adressen 2003:e9:f74a:ecf8::/64 zur Verfuegung. Das sind 18 446.744.073.709.551.616 IP-Adressen im Bereich von 2003:00e9:f74a:ecf8:0000:0000:0000:0000 bis 2003:00e9:f74a:ecf8:ffff:ffff:ffff:ffff. An dem Beispiel kann man schon zwei Sache feststellen: fuehrende Nullen kann man in einem Bereich zwischen 2 Doppelpunkten weglassen. Besteht der Bereich nur aus Nullen, kann man ihn auch ganz weglassen und trennt nur durch :: Ein anderer Prefix ist noch /56, das sind 256 IP-Adressen. Und wer in Mathematik nich so gut ist, fuer den gibt es Kalkulator
Global address/local address(ULA)
Schauen wir uns die Netzwerkkonfiguration unseres DSL-Routers an:
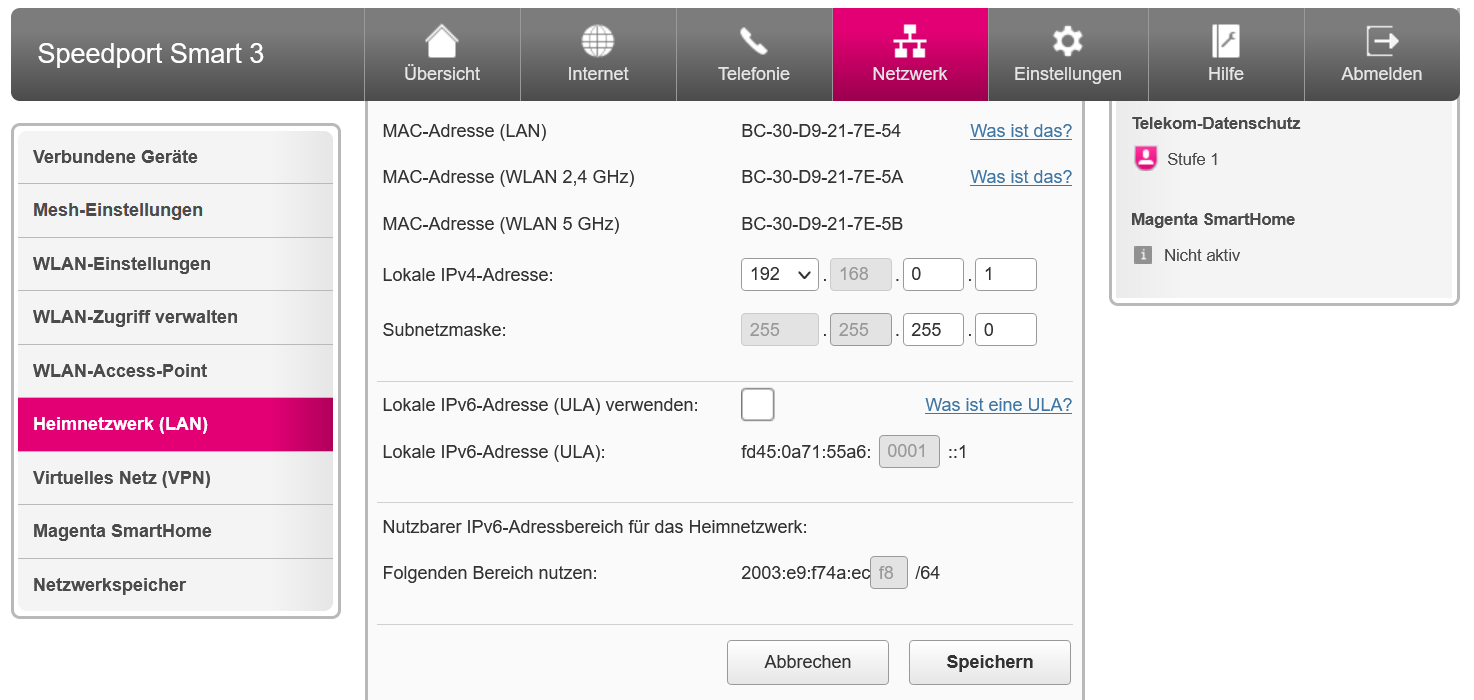
Ganz unten haben wir einen nutzbaren IPv6 Adressbereich fuer das Heimnetzwerk. Das grau hinterlegte Feld ist nicht fest. Das heisst: leider Gottes wechselt dieser Adressbereich alle 24 Stunden. Sofern die IPv6 Adressen im Heimnetzwerk per DHCP vergeben werden, ist das fuer die Endgeraete kein Problem. Im Kubernetes-Cluster passiert die interne Adressvergabe anders. An dieser Stelle muessen wir auf Unique Local Adresses (ULA) bzw. Unique Local Unicast ausweichen. Im IPv6 Adressbereich gibt es dazu den Prefix fc::/7. Das ist vergleichbar mit 10:0.0.0/8 oder 192.168.0.0/16 im IPv4 Bereich. Es kann also zu Ueberschneidungen bei 2 privaten bzw. lokalen Netzen kommen. Wie aber im Bild zu sehen ist, hat uns unser Provider auch einen lokalen Adressbereich zugewiesen. Dieser befindet sich im Prefix fd::/7, hier fd45:0a71:55a6:0001::1 Dieser Bereich ist fest und somit fuer unseren Kubernetes-Cluster geeignet
K3S-Startoptionen
Vorbedingung ist die Aktualisierung von K3S auf mindestens Kubernetes 1.21, das aktuellste hier 1.21.4 Dazu koennen wir den Upgrade-Controller installieren:
kubectl apply -f https://github.com/rancher/system-upgrade-controller/releases/download/v0.6.2/system-upgrade-controller.yaml
Und dann den Upgrade Plan:
apiVersion: upgrade.cattle.io/v1
kind: Plan
metadata:
name: server-plan
namespace: system-upgrade
spec:
concurrency: 1
cordon: true
nodeSelector:
matchExpressions:
- key: node-role.kubernetes.io/master
operator: In
values:
- "true"
serviceAccountName: system-upgrade
upgrade:
image: rancher/k3s-upgrade
version: v1.21.4+k3s1
Standardmaessig ist in K3S ein IPv4 Netz fuer PODs festgelegt. Wir ueberschreiben diese Option in
/etc/systemd/system/k3s.service und deaktivieren auch Flannel, da dieses nicht IPv6 faehig ist. IPv6 DualStack wird auch in den Startoptionen aktiviert.
# ...
ExecStart=/usr/local/bin/k3s \
server \
--no-flannel \
--disable servicelb \
--kube-apiserver-arg service-cluster-ip-range=10.43.0.0/16,fd45:a71:55a6:1:2:1::/116 \
--kube-apiserver-arg feature-gates="IPv6DualStack=true" \
--kube-controller-manager-arg cluster-cidr=10.42.0.0/24,fd45:a71:55a6:1:2:2::/96 \
--kube-controller-manager-arg feature-gates="IPv6DualStack=true" \
--kube-controller-manager-arg service-cluster-ip-range=10.43.0.0/16,fd45:a71:55a6:1:2:1::/116 \
--kube-controller-manager-arg node-cidr-mask-size-ipv4=24 \
--kube-controller-manager-arg node-cidr-mask-size-ipv6=96 \ # 118
--kubelet-arg feature-gates="IPv6DualStack=true" \
--kube-proxy-arg feature-gates="IPv6DualStack=true" \
--kube-proxy-arg cluster-cidr=10.42.0.0/24,fd45:a71:55a6:1:2:2::/96
Service Config neu laden und Service neu starten
systemctl daemon-reload
systemctl restart k3s.service
Calico</a> ist ein weiteres Netzwerk-Plugin für Kubernetes. Es arbeitet intern mit BGP-Routen und kann diese auch in die Welt exportieren. Ausserdem ist es IPv6-faehig. Calico wird meistens mit so einem Manifest deployed. Vorsicht: Die mitgelieferten CRDs sind versionsabhaengig von der Image-Version. Wenn man diese aktualisiert, dann muss man auch die CRDs aktualisieren. Weiterhin sind 4 Parameter wichtig:
Im oberen Teil die IP Konfiguration des Plugin:
"ipam": {
"type": "calico-ipam",
"assign_ipv4": "true",
"assign_ipv6": "true",
"nat-outgoing": "false",
"ipv4_pools": ["10.42.0.0/24"],
"ipv6_pools": ["fd45:a71:55a6:1:2:2::/96"]
},
Wir aktivieren IPv6 Pool und tragen die IP-Netze fuer Cluster vom K3S Startup Script ein. Weiter unten kommen diese Definitionen nochmal im Deployment als Env Variablen:
- name: CALICO_IPV4POOL_CIDR
value: "10.42.0.0/24"
- name: CALICO_IPV6POOL_CIDR
value: "fd45:a71:55a6:1:2:2::/96"
Im selben Areal aktivieren wir IPv6 NAT nach aussen, da wir keine festen ausgehenden IPv6 IPs haben:
- name: CALICO_IPV6POOL_NAT_OUTGOING
value: "true"
Als letztes gibt es die Option in Felix, IPv6 zu aktivieren. Da ist der Agent, der auf jedem Node in einem Pod laufen soll:
- name: FELIX_IPV6SUPPORT
value: "true"
Alle anderen Werte sind default. Nach dem Deployen sollte es im kube-system namespace zwei laufende PODs geben. Einen Controller und mindestens einen Node-Pod:
# kubectl -n kube-system get pods | grep cali
calico-node-twxmf 1/1 Running 0 34m
calico-kube-controllers-74b8fbdb46-slhxn 1/1 Running 0 34m
Wenn diese PODs nicht laufen, muss dies erst untersucht werden, ehe es weitergeht. Meist hat man sich mit den IP-Adressen verhauen, was dann im Log angemeckert wird.
Ob Calico im Cluster funktioniert, sehen wir an einem busybox deployment oder jeden neu gestarteten POD mit einer shell.
bash-5.0# ifconfig eth0
eth0 Link encap:Ethernet HWaddr 72:51:2B:80:AE:E4
inet addr:10.42.0.194 Bcast:10.42.0.194 Mask:255.255.255.255
inet6 addr: fd45:a71:55a6:1:2:3000:0:f01/128 Scope:Global
inet6 addr: fe80::7051:2bff:fe80:aee4/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1440 Metric:1
RX packets:25 errors:0 dropped:0 overruns:0 frame:0
TX packets:25 errors:0 dropped:1 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:2674 (2.6 KiB) TX bytes:2590 (2.5 KiB)
Der POD hat eine IPv4 und eine IPv6 Adresse aus unserem Adressbereich aus der calico Konfig.
bash-5.0# ping ipv4.google.com
PING ipv4.google.com (172.217.19.78): 56 data bytes
64 bytes from 172.217.19.78: seq=0 ttl=58 time=10.722 ms
64 bytes from 172.217.19.78: seq=1 ttl=58 time=10.592 ms
bash-5.0# ping ipv6.google.com
PING ipv6.google.com (2a00:1450:4016:80a::200e): 56 data bytes
64 bytes from 2a00:1450:4016:80a::200e: seq=0 ttl=118 time=21.472 ms
64 bytes from 2a00:1450:4016:80a::200e: seq=1 ttl=118 time=21.450 ms
Damit haben wir ueberprueft, ob die Namensaufloesung funktioniert und wir Netzwerkverbindung mit IPv4 und IPv6 in die Welt haben. Wenn die Namensaufloesung nicht funktioniert, sollte man ueberpruefen, ob der CoreDNS Service laeuft (ggf. POD neu starten) und die Service-IP vom DNS (aus /etc/resolv.con) erreichbar ist. Das Service-Netz muss sich innerhalb des Cluster-Netz befinden! Wenn die Netzwerkverbindung nicht funktioniert, sollte man erstmal probieren, ob es vom Node aus klappt. Ist das der Fall, hilft noch Kontrolle der IP-Forwarding Rules im Kernel
# sysctl net.ipv4.conf.all.forwarding
net.ipv4.conf.all.forwarding = 1
# sysctl net.ipv6.conf.all.forwarding
net.ipv6.conf.all.forwarding = 1
Im ip6tables-save -t nat sollte es eine MASQUERADE Rule nach aussen geben.
Auch zur Kontrolle, ob Calico 2 IP-Pools angelegt hat:
# kubectl get ippools.crd.projectcalico.org
NAME AGE
default-ipv4-ippool 39m
default-ipv6-ippool 39m
Traefik Ingress/Klipper Service Loadbalancer
Da nun die Verbindung mit IPv6 von innen funktioniert, wollen wir von aussen Dienste erreichbar machen. Gemeinhin geschieht das ueber einen Ingress-Controller. Im K3S kommt standardmaessig Traefik zum Einsatz. Dieser hat im K3S eine ganz besondere Eigenart. Standardmaessig deployt das Helmchart “traefik” einen Service vom Typ LoadBalancer. Ohne Cloud Controller bekommt man so keine Verbindung nach draussen, weswegen die externe ServiceIP auf Pending stehenbleibt. Rancher deployed nun IM K3S eine Resource vom Typ DaemonSet, welches einen POD mit HostNetwork erzeugt und somit einen Port dort nach draussen oeffnet. Standardmaessig ist das Port 80 und 443, zusaetzlich noch 9000 fuer Metrics und selbst definierte. Gestartet wird in diesem svclb-POD ein Image namens klipper-lb. Dieses wiederum laeuft in einem Loop und richtet beim Starten zwei iptable-Regeln fuer diesen Loadbalancer Service und Port ein. Also je Port wird ein weiterer Container im POD gestartet. Zwei Sachen fehlen hier:
IP->Port Beziehung. Ich kann also nur eine IP pro Port binden. Bei DualStack habe ich aber eine IPv4 und eine IPv6. Das lehnt das DaemonSet ab wegen doppelten Eintraegen fuer HostPort.
Hier der Hotfix: In den Startoptionen von K3S deaktivieren wir diesen Dienst mit --disable servicelb
Erstmal Traefik mit DualStack Option deployen. Das kann in der Datei /var/lib/rancher/k3s/server/manifests/traefik.yaml geaendert werden:apiVersion: helm.cattle.io/v1
kind: HelmChart
metadata:
name: traefik-crd
namespace: kube-system
spec:
chart: https://%{KUBERNETES_API}%/static/charts/traefik-crd-9.18.2.tgz
---
apiVersion: helm.cattle.io/v1
kind: HelmChart
metadata:
name: traefik
namespace: kube-system
spec:
chart: https://%{KUBERNETES_API}%/static/charts/traefik-9.18.2.tgz
set:
global.systemDefaultRegistry: ""
valuesContent: |-
logs:
general:
level: DEBUG
access:
enabled: true
rbac:
enabled: true
service:
spec:
ipFamilies:
- IPv4
- IPv6
ipFamilyPolicy: RequireDualStack
externalIPs:
- 192.168.0.15
- 2003:e9:f712:a22f:a61f:72ff:fe56:1e9e
ports:
traefik:
expose: true
websecure:
tls:
enabled: true
podAnnotations:
prometheus.io/port: "8082"
prometheus.io/scrape: "true"
providers:
kubernetesIngress:
publishedService:
enabled: true
priorityClassName: "system-cluster-critical"
image:
name: "rancher/library-traefik"
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
Neben der superwichtigen Option RequireDualStack schalten wir auch Logging mit ein.
Wenn der Traefik-Service deployed ist, holen wir uns die zugewiesenen IP-Adressen ab:
$ kubectl -n kube-system get services traefik -o jsonpath="{.spec.clusterIPs}"
["10.43.206.211","fd45:a71:55a6:1:2:1:0:db1"]
und tragen die in das folgende DaemonSet ein:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: svclb-traefik
namespace: kube-system
spec:
selector:
matchLabels:
app: svclb-traefik
template:
metadata:
labels:
app: svclb-traefik
spec:
containers:
- env:
- name: SRC_PORT
value: "9000"
- name: DEST_PROTO
value: TCP
- name: DEST_PORT
value: "9000"
- name: DEST_IP
value: 10.43.206.211
image: rancher/klipper-lb:v0.2.0
imagePullPolicy: IfNotPresent
name: lb-port-9000
ports:
- containerPort: 9000
hostPort: 9000
name: lb-port-9000
protocol: TCP
resources: {}
securityContext:
capabilities:
add:
- NET_ADMIN
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
- env:
- name: SRC_PORT
value: "80"
- name: DEST_PROTO
value: TCP
- name: DEST_PORT
value: "80"
- name: DEST_IP
value: 10.43.206.211
- name: DEST_IP6
value: fd45:a71:55a6:1:2:1:0:db1
image: mtr.external.otc.telekomcloud.com/eumel8/klipper-lb:dual-stack
imagePullPolicy: IfNotPresent
name: lb-port-80
ports:
- containerPort: 80
hostPort: 80
name: lb-port-80
protocol: TCP
resources: {}
securityContext:
capabilities:
add:
- NET_ADMIN
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
- env:
- name: SRC_PORT
value: "443"
- name: DEST_PROTO
value: TCP
- name: DEST_PORT
value: "443"
- name: DEST_IP
value: 10.43.206.211
- name: DEST_IP6
value: fd45:a71:55a6:1:2:1:0:db1
image: mtr.external.otc.telekomcloud.com/eumel8/klipper-lb:dual-stack
imagePullPolicy: IfNotPresent
name: lb-port-443
ports:
- containerPort: 443
hostPort: 443
name: lb-port-443
protocol: TCP
resources: {}
securityContext:
capabilities:
add:
- NET_ADMIN
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
operator: Exists
- effect: NoSchedule
key: node-role.kubernetes.io/control-plane
operator: Exists
- key: CriticalAddonsOnly
operator: Exists
updateStrategy:
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
type: RollingUpdate
Das Programm laeuft mit einem Fork von klipper-lb. Es hat die zusaetzliche Variable DEST_IP6 und legt, wenn diese vorhanden ist, die IPv6 Iptables an.
Voila! Fortan sollten unsere Dienste ueber IPv6 erreichbar sein. Und unsere Workload hat Verbindung zur IPv6 Welt. War das nicht einfach?
